Work in progress
This version may be updated without notice.
| [Up] |
| Work in progressThis version may be updated without notice. |
Copyright © INRIA
is a powerful XML schema technology built on technologies.
has the ability to select its content models contextually, and to refactor them dynamically. That's why ta are active and much more efficient than other schema technologies.
Moreover, can be used to define reusable active data type libraries that can also be used in applications.
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
Note that for reasons of style, these words are not capitalized in this document.
The following specifications are part of the technologies.
1.1 Why another schema technology ?2 Basics
1.2 What is ?
2.1 Terminology3 Active content models
2.2 Use case
3.1 Step processing4 Types
3.2 Primitive model processing
3.3 Occurrences boundaries
3.4 Material lists and exceptions
3.5 Attributes lists
3.6 Text content list items
3.7 Assertions lists
3.8 Interim processing
3.9 Reusability
4.1 Data types5 Building4.1.1 Using and defining data types4.2 Element classes
4.1.2 Internal data model representation
4.1.3 Parsing
4.1.4 Type inheritance
4.1.5 Semantic support
4.1.6 Functions binding4.1.6.1 Comparison function binding4.1.7 Augmentation
4.1.6.2 Counterpart function binding
5.1 References to namespace URIs6 Processing
5.2 Multi-schema support
5.3 Integration with5.3.1 Integration with EXP5.4 Documenting
5.3.2 Integration with
5.3.3 Relationship with
5.5 Model inconsistency5.5.1 Non deterministic content model avoidance
6.1 Invoking7 ASL module reference
6.2 Batch processing
6.3 Localized validation
6.4 Errors
7.1 Elements
7.2 Foreign attributes
7.3 Predefined properties
7.4 Extended XPath functions
7.5 Externalisable features
A Glossary
B Related specifications
C Common modules
D Lists
D.1 Examples listE ta for ASL
D.2 Figures list
E.1 ASL definitionsF Known implementations
E.2 General purpose messages
An XML Schema is the expression of some assertions expected on an XML document class. Assertions on XML documents ensure that applications will process them without causing faults. Expressing assertions with schemata ensure that applications developpers will spend most of their time in designing data process and few of their time in controlling them.
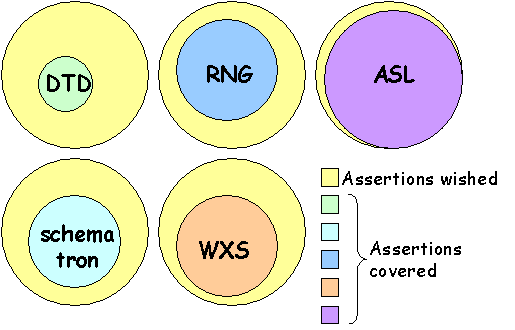
Well known schema technologies are :
| Name | Syntax style | Type | Editor | Specification location | Elem nb |
|---|---|---|---|---|---|
| Document Type Definition (DTD) | non XML syntax | model based | W3C | http://www.w3.org/TR/2004/REC-xml-20040204/ | 8 |
| W3C XML Schema (WXS) | XML syntax | http://www.w3.org/TR/2001/REC-xmlschema-0-20010502/ http://www.w3.org/TR/2001/REC-xmlschema-1-20010502/ http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/ |
42 | ||
| Schematron | rule based | ISO | http://www.ascc.net/xml/resource/schematron/Schematron2000.html | 19 | |
| Relax NG (RNG) | XML syntax XML compact syntax |
pattern based | OASIS ISO |
http://www.oasis-open.org/committees/relax-ng/spec-20011203.html | 28 |
| Newcomer | |||||
| (ASL) | XML syntax | active | INRIA | http://disc.inria.fr/perso/philippe.poulard/xml/active-schema | 20 (*) |
|
The general purposes of a schema technology are :
|
 (*) 20 elements used in schema instances + 4 elements used in active sheets. Schematron, mentioned above, was designed for validation. Unlike other schema technologies, it is not obvious to use it for structured edition. |
Other applications that uses schemata are emerging, such as data binding.
Any schema technology is designed to cover numbers of assertions expressed. However, the existing schema technologies can't express many constraints like the following listed below. Some technologies will cover the feature, others won't ; sometime none.
As shown in the picture below, ASL covers constraints types listed above and many others that existing schemata technologies can't.
is an module, and ruled by the relevant concepts described in the specifications.
is a schema technology based on very simple concepts. Enhanced with , deals with schemata problematics with greater efficiency than other schema technologies.
An may be used both for validation and for structured edition, and many other purposes.
With its simple concepts and low number of elements, is easy to learn and easy to use, because the schema follows the structure of the document. An is also friendly human-readable : it's easy to understand at first glance the content model of an element.
Finally, the capabilities of the technology cover the following purposes :
has been designed with the intention to keep XML document classes as is, without structure adjustment on the pretext that a content model can't be expressed with the schema technology choosen. The motivation to design an XML structure must not be lead by any schema technology.
deals with XML documents representing both ta and instances through an abstract data model. XML documents representing ta and instances must be well-formed in conformance with XML 1.0 and must conform to the constraints of XML Namespaces.
An is a flat set of definitions. The materials defined inside an must endorse the same namespace URI, but several storage units (files) may be part of the same schema if they share the same target namespace URI.
A material definition is composed of elementary steps that are processed independently. Steps may be primitive models or step containers for others steps. Each primitive model is processed in three phases; for example, when validating:
Steps that are applied on element definitions are called active content models.
can't constraint comments, processing instructions, and namespaces declarations obviously; however, specific assertions may restrict their usage anyway.
The term "material" is used to represent :
The term "content material" is used to represent :
A candidate material is the material or content material -according to the context- to check with the schema. It may be :
Additionally, a candidate material may hold the place before the first material of a list (the child nodes of an element) or after its last material ("cap candidate").
A schema client handler is a component of an application that uses ta ; it processes lists of allowed material provided by the schema at runtime.
For example, a validator handler checks if the material found in the source document matches a list computed in a given step.
A schema client handler uses callbacks to process lists because it doesn't select the step to apply ; the schema engine does. Anyway, the entry point of an application that processes an is an element, or a document ; such application should define what to do with the callbacks :
Additionally, when an element has been processed, the schema client handler may process its subelements at user option.
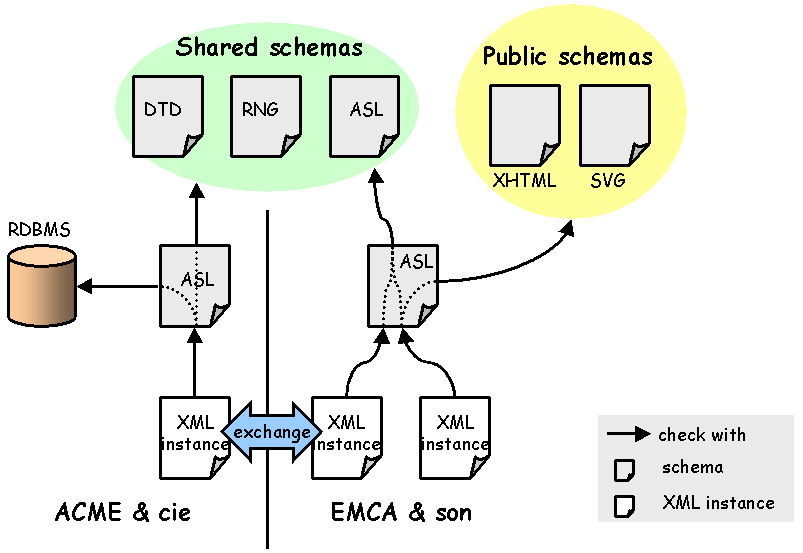
This use case illustrates that ta are context dependant.
In this scenario, two companies ACME and EMCA are exchanging XML documents. They are sharing the same base set of schemata, but both are extending it for special purpose usage:
The schema soup consist on a legacy DTD (without namespaces), a Relax NG schema, a brand new , and other well known schemata for XHTML and SVG.
in conjunction with offers all means to process such a case very efficiently:
Content models are element content definitions that defines which material content is allowed, when it is allowed, and how many times.
An is a model based schema ; however, unlike other schema technologies, the models defined are active, that is to say that :
For this purpose, content models are divided in elementary checking steps, that may produce a maximum of one of the following primitive model types :
Steps set the scopes of the model types, but can also be used as step containers (with the <asl:step> or <asl:interim> elements) ; XCL can be used advantageously to control which step or substep to use. A <asl:step> element is also a container for attributes (with the <asl:attribute> element), but the list of authorized attributes must be computed in separate steps of those used for content models.
Thus, a content model is processed step by step, each step may be repeated or discarded on behalf of the following step, or on behalf of an interim step. When repeating, its content model may be kept or refactoried.
Finally, additional constraints may be computed to check the validity of an element or to check if an element can be inserted (with the <asl:assert> element).
A step is an elementary unit of process that consists on drawing up lists of materials available and assertions. A step may be a container step, that may contain substeps, or a primitive content model step, that can't contain substeps.
When the content of an element must be checked, the steps defined in the element definition are evaluated on a global sequence. During this process, after a material (text or element) found within the element has been checked with the current step, the next material to check is then selected. According to its settings, the step used may be reused as is, refactoried, paused, or terminated ; the next step is then used.
In addition to content models, a step may also be used to draw up lists of attributes, lists of assertions, and lists of data type matchers. Attributes lists can't be mixed with content materials lists ; assertions lists can be draw up in any step ; data type matchers lists are only found within attribute definitions (<asl:attribute>) and data type definitions.
Steps and material to check are globally progressing on a synchronized reading process.
According to a given step and a given material to check, the following process is applied :
When a content material must be checked for example to test if it is possible to insert an element, the host element definition must be performed step by step until the position of insertion.
Moreover :
A primitive model type is a special step used to establish a list of available material. Once selected, the model type establishes lists of allowed materials and assertions that are transmitted to the host application for candidate material checking. For example, a validator would apply these lists on the material to check (candidate material).
Once a candidate material is selected by the host application, it is used to check if it matches the material of the list :
| primitive model type | application | repeating |
|---|---|---|
| sequence (<asl:sequence>) | the first material of the list may match the candidate material | the list is updated |
| selection (<asl:select>) | any material of the list may match the candidate material | |
| choice (<asl:choice>) | the list remains the same |
To check if a candidate material matches a choice or a selection, the list is browsed sequencially ; the first item that matches the candidate material is retained. To check if a candidate material matches a sequence, the items are tested sequencially according to the occurrences boundaries.
Once a step matches a candidate material, it may be refactoried on user request if it is reused, or kept as is in the conditions of the repeating mentioned in the table above. When a list is updated while repeating, the use counter of the material is incremented ; the material used is discarded from the list if it is no longer usable, according to the occurrences boundaries set.
Once a step ends, the step container process goes on.
Occurences can be set on steps with the attributes :
Elements that allow using this attributes always use 1 as the default value for both attributes. The value "unbounded" for the @max-occurs may be specified ; otherwise, a nul or positive integer may be specified ; finally, an expression may also be specified to compute a dynamic value.
2 predefined properties have been defined to allow the min occurs value to be based on the max occurs value, or the contrary : $asl:min-occurs and $asl:max-occurs.
For example, min-occurs="{count(//foo}" max-occurs="{$asl:min-occurs}" is correct.
Occurences can be set only on steps. Sequences can't have occurrences boundaries (occurences are reported on the material referenced inside). Additionally, when sequences are defined... sequentially, they can be merged. A sequence is always a stable list with no occurrences boundaries.
Instead of :
<asl:sequence>
<asl:element ref-elem="Title"/>
</asl:sequence>
<asl:sequence min-occurs="0"><!-- this is invalid -->
<asl:element ref-elem="Content"/>
</asl:sequence>...use the short form :
<asl:sequence>
<asl:element ref-elem="Title"/>
<asl:element min-occurs="0" ref-elem="Content"/>
</asl:sequence>Occurences may be used in material reference inside select models, but grouping adjacent select models doesn't express the same model. In fact, sequence models are also slightly differents when the subactions are involving the asl:candidate() function, because the entire sequence list is evaluated with the same candidate material, whereas in the other form, it is evaluated with successive candidate material to check in the case of validation.
Occurences [FIXME: can't ???[shouldn't]] be used in material reference inside choice models, because the list is not updated.
When a candidate element has matched a material that specified occurences, the numbers of occurences are decremented for the next usage.
| Element definition example | |
|---|---|
The ASL element definition below mimicks the following familiar DTD declaration : <!ELEMENT Chapter (Title, ((Content, Chapter*) | Chapter+))>
<asl:element name="Chapter">
<asl:sequence>
<asl:element ref-elem="Title"/>
<asl:element min-occurs="0" ref-elem="Content"/>
</asl:sequence>
<asl:choice max-occurs="unbounded"...where asl:candidate() refers to the candidate material at the position it is expected. When the choice step is involved, a <Content> element may or may not have been found. In the first case, the @min-occurs attribute will be set to 0, which denotes that the <Chapter> is optional, and in the second to 1, which denotes that a <Chapter> at least must be found. The @repeating directive of the last step indicates that both the min occurs value and the list have to be computed only once. | |
When involved in a stable step, occurs values are kept unchanged ; when involved in an unstable step, occurs values are actualized.
If a step must be repeating, according to its occurrences boundaries, its content may be kept as is or refactoried, according to the value of the @repeating attribute :
Once a primitive content model occurs the minimum times expected, it must exit as soon as the candidate material doesn't match the material, or as soon as the maximum times expected is reached.
Once a container step occurs the minimum times expected, it must exit as soon as the maximum times expected is reached, or as soon as its substeps are no longer in use.
Steps must inform that they were used with a bubble message. A primitive content model was used if a matching occurs. A container step was used if it received a bubble message that indicates that a substep was used.
A list is an ordered set of material ; as each list item may represent a group of material when a class or type reference is used, or when a namespace URI reference is used, a sublist that disables (<asl:except>) a subgroup may be added ; this sublist may also have its sublist that enables (an exception of an exception) another subgroup and so on. A sublist is defined as content or subcontent of a material.
Of course, an exception must build a list compliant with its target list (in the example above, only elements are concerned).
An element definition may refer to attributes with the <asl:attribute> element ; an attribute reference may be expressed thanks to the @ref-attr attribute, or directly with the @name attribute for private attributes.
Thus, attribute definitions may occur on the top level elements of the schema (and shared with all schemata), or directly within an element definition ; the latters may be without a namespace URI because unprefixed attributes are "belonging" to their host element.
Hereafter, the <person> element uses an attribute defined locally :
<asl:element name="my:person">
<asl:attribute name="role">
<asl:text value="author"/>
<asl:text value="editor"/>
<asl:text value="reviewer"/>
</asl:attribute>
</asl:element>Now, it refers to a sharable and global attribute :
<asl:attribute name="my:role">
<asl:text value="author"/>
<asl:text value="editor"/>
<asl:text value="reviewer"/>
</asl:attribute>
<asl:element name="my:person">
<asl:attribute ref-attr="my:role"/>
</asl:element>Within an element definition, more than one attribute reference or inline definition may occur ; attributes lists are separated lists which must be computed in a separate step to content models.
As attributes are unordered inside their host element, attributes references and local definitions are allowed directly under the <asl:element> element, unlike content models that must be specified within steps. Under the <asl:element> element, if attributes are encountered outside the scope of a step, they are processed as if a step were defined above ; once an explicit step is encountered, the list is applied before running the explicit step. This is important because the attributes references can't be used anymore for disabling/enabling purposes as they just have been consumed.
Only the <asl:select> primitive step is allowed for attribute lists. Once a list of attributes is established, it is applied on the element to check, or transmitted to the host application.
When validating, once an element definition ends, all its attributes must have been matched, except namespaces declarations that are not checked. The same attribute can't be matched by several lists.
Like with other materials, each list item may have a sublist, and items may be arbitrary enabled or disabled in a top list.
Additionally, items are data typed.
Global attributes are defined with the <asl:attribute> element under the root ; local attributes are defined under elements definitions. Global attributes can be used in an other schema, local attributes can't. However, within a schema, local and global attributes are reusable. Global attributes should have their names bound to namespace URI.
Attribute references or inline definition may be specified with occurrences boundaries ; static and runtime values are allowed.
As usual, the default values for both attributes is 1, which denotes that the attribute is mandatory. Hereafter an element definition references an optional attribute :
<asl:element name="my:person">
<asl:attribute min-occurs="0" ref-attr="my:role"/>
</asl:element>Element content models may contain element references or text items ; allow to define which text content is enabled, and where it is enabled, even in mixed contents.
Text content list items are very close to attribute values, except that they are unnamed items (however, a convenient way to "name" text content is to use data types) and appear exclusively in primitive content models, exactly like element references. Attribute values and text contents are text values that data types may constraint.
When processing text, comments and processing instructions are ignored, and adjacent texts are merged.
Within primitive content models, the <asl:text> element is used to introduce a text content material. When involved in a material list, a candidate material matches a text definition if and only if :
A whitespace, in the sense of XML, is a text that contains spaces, tabs, and returns (carriage return, linefeed, or both).
Whitespace candidates are discarded in the following conditions : when a content model is defined with elements and texts that can contains whitespaces, if the candidate material is a whitespace followed by an element that matches an item of the content model, then the whitespace candidate is ignored.
A text item uses the same matchers than those used to define data types and those used in attribute values. A text definition involves the <asl:text> element with :
However, as they may be mixed with element references, only a single matcher can be used at a time, that is to say that 2 text matchers can't be found side by side. When a choice of text matcher is needed, it must be enclosed within an inline type definition, or defined with a type reference. Schemata designers must take care that a step that ends with a text matcher can't be followed by a step that begins with a mandatory text matcher, because the last text matched has been totally consumed by its matcher.
Here is an element that must contain one string beyond a predefined set :
<asl:element name="Role">
<asl:choice>
<asl:text min-occurs="0" value="author"/>
<asl:text min-occurs="0" value="editor"/>
<asl:text min-occurs="0" value="reviewer"/>
</asl:choice>
</asl:element>...and another that may contain any string :
<asl:element name="Para">
<asl:choice>
<asl:text ref-type="xs:string"/>
</asl:choice>
</asl:element>A mixed content may also be defined :
<asl:element name="p">
<asl:choice max-occurs="unbounded">
<asl:text min-occurs="0" ref-type="xs:string"/>
<asl:element min-occurs="0" ref-elem="b"/>
<asl:element min-occurs="0" ref-elem="i"/>
<asl:element min-occurs="0" ref-elem="span"/>
<asl:element min-occurs="0" ref-elem="tt"/>
<asl:element min-occurs="0" ref-elem="a"/>
</asl:choice>
</asl:element>A content model may precisely indicates where and which text content is allowed :
<asl:element name="Person">
<asl:choice>
<asl:text min-occurs="0" value="Mrs"/>
<asl:text min-occurs="0" value="Ms"/>
<asl:text min-occurs="0" value="Mr"/>
</asl:choice>
<asl:sequence>
<asl:element ref-elem="Name"/>
</asl:sequence>
</asl:element>...that could match :
<Person>Mr<Name>Poulard</Name></Person>
...but can't match :
<Person>Mr<Name>Poulard</Name> is french.</Person>
When used directly, the <asl:text> element allow to express simple rules ; for more complex text combinations, the reference to a <asl:type> offers much more flexibility. For example, both following text contents :
<polygon>x=6, y=10, x=37, y=61, x=37, y=16</polygon> <polygon>6, 10, 37, 61, 37, 16</polygon>
...could be defined by the following schema that refers to a custom data type :
<asl:element name="polygon">
<asl:choice>
<asl:text min-occurs="0" ref-type="my:points"/>
</asl:choice>
</asl:element>The definition of this type is shown in the chapter about data types. Notice that a type may be used indifferently in a text content or in an attribute value :
<asl:element name="polygon">
<asl:attribute name="points" ref-type="my:points"/>
</asl:element>A type may also be defined anonymously (and can be used also for attributes definitions) :
<asl:element name="polygon">
<asl:choice>
<asl:text>
<asl:type>
<!-- insert the type definition here -->
</asl:type>
</asl:text>
</asl:choice>
</asl:element>Please refer to the chapter about data types.
Assertions lists are separated lists than can be computed at each step. Once a list of assertions is established, it is applied on the element to check, or transmitted to the host application.
Assertions are additive controls that can't be expressed by content models. Assertions are defined with the <asl:assert> element. Its @test attribute contains an expression that must return true on valid datas, false otherwise. If the assertion to test can't be expressed within this single attribute, its subactions are performed, and the assert is true if the current object is evaluated to true, false otherwise.
For example, the following assertion limits the deepest of an element :
<asl:element name="Chapter">
<asl:assert test="{ count( asl:element()/ancestor::Chapter ) < 4 }">
<asl:desc>Too much nested chapters !</asl:desc>
</asl:assert>
</asl:element>The asl:element() function returns a reference of the element currently tested.
The <asl:interim> element defines a step that marks a pause on the current model in use. It allows other content models to be applied, but other special purpose processing may be intend. When ending, the model in pause goes on.
An interim step is an unstable step launched only when its host model matched.
<asl:element name="foo">
<asl:choice max-occurs="10" min-occurs="5">
<asl:element ref-elem="bar"/>
<asl:element ref-elem="goo">
<asl:interim>
<asl:sequence>
<asl:element max-occurs="2" min-occurs="2" ref-elem="hoo"/>
<asl:element max-occurs="3" min-occurs="3" ref-elem="woo"/>
</asl:sequence>
</asl:interim>
</asl:element>
</asl:choice>
</asl:element>Each time the <goo> element will be matched, the sequence of <hoo> and <foo> must be applied, as shown in the instance above which is valid with the schema. |
<foo> <bar/> <!-- 1st choice --> <goo/> <!-- 2nd choice --> <!-- interim model starts --> <hoo/> <!-- 1st occur of the 1st elem --> <hoo/> <!-- 2nd --> <woo/> <!-- 1st occur of the 2nd elem --> <woo/> <!-- 2nd --> <woo/> <!-- 3rd --> <!-- interim model ends --> <bar/> <!-- 3rd choice --> <bar/> <!-- 4th choice --> <bar/> <!-- 5th choice --> </foo> |
This structure is somewhat unusual in other schema technologies : when a content model is defined within an element referenced, it means that this content model is applied on the children of the candidate element.
The <asl:interim> element denotes that the content models defined within are applied on the next sibling candidate elements.
There is no structure that defines groups of attributes in , but it is possible anyway to select one set or another with an interim step : once an attribute matched, an additional attribute list may be provided.
An interim step may be advantageously used for complex combination descriptions. It is possible to define an interim step that occurs when an element has been matched, but that draw up an attribute list, or the opposite. It is also possible to define an interim step inside an element or attribute that have been involved in another interim step.
As the <asl:attribute> element is used both to define an attribute and to refer to one, the <asl:interim> element must be used without causing a conflict. This can be avoid only when using it on attribute references. On the other hand, attribute definitions can't contain the <asl:interim> element.
An <asl:interim> step can also be used within text and type definitions. In this case, its substeps must deal exclusively with text and type matchers. More generally, an interim step must not be used to check additional constraints on attributes or elements because a text parsing is currently in course and may fail without causing fault because another text parsing may suit later. It would be too problematic to deal with possible additional constraint checking in the case where a type, for example, relies on another type which could match whereas its parent type doesn't.
The @replace attribute indicates if the interim model replaces or not the host model :
When an interim step replaces definitively an upper model, this model is discarded without further occurrence boundaries checking.
Numbers of ASL elements have an @id attribute that identifies the element with a qualified name.
Any identified attribute may be reused thanks to the <asl:use> element. The @scope attributes indicates if the target element must be used itself, or only its content (by default).
Additionaly, when only a part of a definition would be convenient to reuse, the <asl:block> element can be use to set the boundaries of the reusable part. For other ASL elements, the <asl:block> element is totally neutral (it is traversed as if there were only its content). When using a group, the scope must be set to the content.
It is strongly recommended for identifiers to be qualified names ; the namespace URI of identifiers should be the same of the target namespace URI of the host schema.
An ID bound to a namespace URI is looked up within the set of schemata bound to the same namespace URI.
For example, the ASL schema for OASIS XML Catalog uses this elements.
Types differ whether they are related to textual datas or elements. This specification talks about data types (<asl:type>) or element classes (<asl:class>).
Data types apply both on attribute values and text content, designated as textual data. A textual data is a string that can be parsed into a typed data. Parsing a textual data is the operation that consist on sequencially converting the characters into the typed data according to a data type. A typed data consists on:
Data types may be composite, that is to say composed of sequences of data types. Once the first data type of the sequence ends to parse the textual data, the second try to parse the remainder, and so on.
From the point of view of an attribute or a text content, the parsing succeeds if and only if a typed data has been parsed succesfully with no remainder. That is to say that if the data type is a composite data type, the last data type of the sequence must consume all the remainder, otherwise the entire parsing fails.
provides means to define new data types, for example by adding constraints on an existing type, like W3C XML Schema does. It is possible for example to restrict the values of an integer to be between 1 and 365.
When defining a data type, it is possible to apply constraints during or after parsing. Constraints may be applied on the lexical value and/or the logical value and its components (see internal data model representation).
A data type can be defined with a name with the <asl:type> element and its @name attribute, or anonymously directly where it is needed. Named data types are easily reusable. Anonymous data types should be designed for single shot usage.
Named types are defined at the top level with the @name attribute of the <asl:type> element. Anonymous types are defined anywhere a type is expected without its @name attribute. When a type is expected, it is defined anonymously, or referred to by its name with the @ref-type attribute of the <asl:attribute> and <asl:text> elements.
Data types are defined on behalf of :
The same type definition may be referred both in an attribute value and in a text content.
For example, the following type definition is reusable :
<asl:type name="asl:min-occurs">
<asl:choice>
<asl:text ref-type="xs:nonNegativeInteger"/>
<asl:text ref-type="adt:expression"/>
</asl:choice>
</asl:type>The above definition is explicitely a choice step ; the first type that matches the text value is kept.
If an attribute is defined with a single type, its definition uses the @ref-type attribute. Otherwise, this attribute is missing and the content of the attribute definition may refer to a list of types. The attribute definitions below are equivalent; the former uses a type that aggregates those that the latter uses directly:
<asl:attribute name="min-occurs" ref-type="asl:min-occurs"/>
<asl:attribute name="min-occurs">
<asl:text ref-type="xs:nonNegativeInteger"/>
<asl:text ref-type="adt:expression"/>
</asl:attribute>The attribute definition act as a choice step ; the first type that matches the attribute value is kept.
The last mean to define a type, is to extend an existing type, by using the @base attribute, to specify which type it is based on.
<asl:type base="xs:integer" name="xs:nonNegativeInteger">
<!-- type definition here -->
</asl:type>The definition consists on steps that use matchers.
As explained hereafter, a type may be :
A composite data is a typed data produced by a composite type, that is to say, a typed data that may contain other typed datas. A non-composite data such as an xs:int is a typed data with a single value; it can't contain other typed datas.
The formal type of a composite type is adt:XComponent.
A typed data is a cross operable object for which its attributes contains characteristics of the type for the specific value (facets), and its children contain the parsed datas (values).
When parsing a text value, the engine try to build an internal data model ; the parsing fails when the target object fails to construct, or if some additional assertions -introduced with the <asl:assert> element- fails. Otherwise, the parsing succeeds.
Runtime data types are parsed as expressions, and the object expected can be retrieved only at runtime ; thus, errors may be raised at runtime. Runtime data types are involved thanks to the adt:expression type. Notice that at runtime, an adt:expression may also return non XML-aware objects; the type of such objects, known as marker types, are out of the scope of this specification. Please refer to the Active Datatypes specification for further information.
The parsing result may be constructed with the help of other types ; in this way, the data model obtained may be any arbitrary complex structure. provide the <asl:item> element to build a made-to-measure data model. When built with actions, a text value is always parsed to a typed data that is a cross operable object.
For example, the fr:date type could be defined to parse a value such as 10 juin 1969, and return an object that could be accessed thanks to XPath ; in the context of its value :
Facets are attributes exposed in addition to the data model. They have a name and a value that is not necessary a string, and can be constraint.
For example, an xs:integer have the facet @adt:total-digits that contains the number of digits of the integer. An assertion on this facet could be set like this :
<asl:assert test="{ @adt:total-digits < number(2) }"/>WXS datatypes are exposed in in a slightly different manner than in the W3C XML Schema specification, because the base concepts are somewhat different, specifically on the hierarchy model. However, as the same features are covered and as they share the same semantics, they are compatible. just provides a different view of the WXS datatypes.
The Active Datatypes specification describes how WXS datatypes can be used in . In particular, it names the WXS facets to use as attributes in typed datas.
The core facets are :
The facets are bound to the http://www.inria.fr/xml/active-datatypes namespace URI for convenience : typed datas may have their own attributes (user defined) that can't be in conflict with the facets.
The value of the object itself may be used to express constraints. For example, to constraint an integer to be less than or equal to 31 :
<asl:assert test="{ value( . ) <= number( 31 ) }"/>Text parsing is very close to content model parsing : many elements (<asl:choice>, <asl:except>, <asl:interim>...) are accomplishing the same function for text parsing that for content model parsing. The difference is that the material used to feed the context are related to text :
A type definition uses text matchers that are text values, regular expressions or other type definitions that define which character sequences are allowed in the type definition. When all matchers expected in a type definition has been involved and that a character sequence remains, the type returns the result data model with a remainder. If the host material that was using this type definition is itself a type definition, the host type goes on applying the matching with the remainder, and so on until the host is an attribute definition or a text content model. At this stage, if the remainder is involved in the next type or matcher, the process is repeated. When the host attribute or text content model definition definitively ends, the remainders must have been consumed. Otherwise, the matching fails.
A text matcher is involved with the @value, @match, or @ref-type attributes of the <asl:text> element :
Finally, if the <asl:text> element has none of the above attributes, the type definition used will be the first found in the context after running the element content, otherwise it won't match anything.
Text matchers may be optional, and may be repeated. The repetition may be specified with the @min-occurs and @max-occurs attributes.
Repetitions may be impossible to process without the help of separators that are not involved in the matching process.
For example, 123456 can't match two xs:integer whereas 12,3456 can match one xs:integer, the "," separator, and another xs:integer. If the type my:twoDigits was defined to match two digits, then 123456 could match three my:twoDigits.
However, my:twoDigits could work as explained above only if it doesn't rely on an xs:integer, constraint by an aditionnal assertion set on its facets, like this:
<asl:assert test="{ @total-digits < number(2) }"/>The following sequence definition is used to match x=12,y=34 but not x=,y=34 :
<asl:sequence>
<asl:text ignore="yes" value="x="/>
<asl:text ref-type="xs:nonNegativeInteger"/>
<asl:text ignore="yes" value=",y="/>
<asl:text ref-type="xs:nonNegativeInteger"/>
</asl:sequence>The @ignore attribute is used to specify that the value matched is not used to build the result data model. The others matched character sequences are used to build the result data model as unnamed items which are of the type xs:nonNegativeInteger in this example.
To build the data model with a named item, or to compute a value other than those matched, the @item-value and @item-name attributes may be used :
<asl:text item-name="x" item-value="{current()}" ref-type="xs:nonNegativeInteger"/>As shown above, the current object is set to the matched value before item creation.[FIXME: not sure, remove it ?[ After, the previous value of the current object is restored.]]
Additionally, this attributes (@item-value and @item-name) may be separated ; in this case, the next matched value that follows a matched value that indicates an item name, must specify an item value.
<asl:text item-name="x" value="x="/>
<asl:text item-value="{current()}" ref-type="xs:nonNegativeInteger"/>In short, a matched content may be :
Finally, the result data model may be construct with arbitrary additional items with the <asl:item> element, and optionally its @name attribute. When encountered, this element wraps in a composite data (its type is adt:XComponent) all subitems produced; if empty, the item is not created.
<asl:item name="point">
<asl:sequence>
...
</asl:sequence>
</asl:item>The @base attribute of a type definition (<asl:type>) indicates that the type is based on another type, called the base type. The base type is used to parse the input text data before using the inner type definition. The type definition may indicate how to initialize the typed data and how to parse further.
For this purpose, the @init attribute indicates how to initialize the typed data ; when present, it contains an expression that will be computed to initialize the typed data ; common usage are explained below :
In any case, the current object is set to the typed data produced by the base type. Additionally, the $asl:data property is set to the initialized typed data. While parsing, the typed data initialized may be updated or its content appended if it is a composite data; it can be referred thanks to the $asl:data property.
The @parse attribute is involved after the @init attribute to indicate which text data will be used for the parsing. If missing, the type will parse the remainder that has not been parsed by the base type. Otherwise, it contains an expression that will return the text to parse.
When the @base attribute of a type definition is missing, it is equivalent to set the base type to xs:string, the @init attribute to "void", and the @parse attribute to "{.}" : the effect is that the entire text value is parsed with the type definition.
For example, the following type is based on an integer:
<asl:type base="xs:int" init="{.}" name="temperature">
<!--temperature stuff here-->
</asl:type>A typed data created by this type is of the xs:int type; the inline part of the definition was parsing the remainder, if any (the @parse attribute is missing).
The following type will remove undesirable spaces from the input text value before choosing which text has been selected :
<asl:type init="" name="size" parse="{asl:compacted-string(.)}">
<asl:choose>
<asl:text value="big"/>
<asl:text value="small"/>
</asl:choose>
</asl:type>In this example, the remainder -if any- is also cleaned of trailing spaces.
[FIXME: what about an optional attribute item-name='name' to do things like for asl:text ?]When parsing, each time a matcher has matched, the typed data matched is set as the current object, that the matcher can refer to build the data model if the @ignore attribute is not set to "yes". For example, the following text matcher builds an item with the name "x" and which value is the typed data given by a text parsed as a non-negative integer :
<asl:text item-name="x" item-value="{current()}" ref-type="xs:nonNegativeInteger"/>
When the item of the data model has been built, it is set to the $asl:data property if it does not exist, or appended to its child if it already exists. This property is a cross-operable object that can be referred while building the data model.
The $asl:data property in one hand and the current object in the other hand are not handling the same datas : the current object handles the last parsed data, whereas the $asl:data property handles the previous one; if the last parsed data is not ignorable, it is appended to the $asl:data property and became the new $asl:data property if it is a composite data. Once the composite data ends to parse, its parent will be restored as the $asl:data property.
Each time the <asl:item> element is encountered, a new empy typed data (its type is adt:XComponent) is appended to the $asl:data property (which is replaced too as explained above). Its subactions will define its content. After running them, if the current typed data is still empty, it is removed. In short, empty items are ignored.
Each time an item name and an item value are encountered, they complete the typed data with a single named item.
| Polymorphic attribute value | |
|---|---|
In this example, one defines an attribute value that both matches the following kind of content : <polygon points="x=6, y=10, x=37, y=61, x=37, y=16"/> <polygon points="6, 10, 37, 61, 37, 16"/> The schema below parses such attribute values with an anonymous type :
<asl:element name="polygon">
<asl:attribute name="points">
<asl:type init="{adt:XComponent()}" parse="{asl:compacted-string(.)}">
<asl:item id="pointXY-item">
<asl:sequence>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text ignore="yes" value="x="/>
<asl:text item-name="x" item-value="{.}" ref-type="xs:nonNegativeInteger"/>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text ignore="yes" value=","/>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text ignore="yes" value="y="/>
<asl:text item-name="y" item-value="{.}" ref-type="xs:nonNegativeInteger"/>
</asl:sequence>
</asl:item>
<asl:sequence>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text ignore="yes" min-occurs="0" value=",">
<asl:interim min-occurs="0">
<asl:use ref-id="pointXY-item" scope="global"/>
</asl:interim>
</asl:text>
</asl:sequence>
</asl:type>
<asl:type init="{adt:XComponent()}" parse="{asl:compacted-string(.)}">
<asl:item id="point-item">
<asl:sequence>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text item-name="x" item-value="{.}" ref-type="xs:nonNegativeInteger"/>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text ignore="yes" value=","/>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text item-name="y" item-value="{.}" ref-type="xs:nonNegativeInteger"/>
</asl:sequence>
</asl:item>
<asl:sequence>
<asl:text ignore="yes" min-occurs="0" value=" "/>
<asl:text ignore="yes" min-occurs="0" value=",">
<asl:interim min-occurs="0">
<asl:use ref-id="point-item" scope="global"/>
</asl:interim>
</asl:text>
</asl:sequence>
</asl:type>
</asl:attribute>
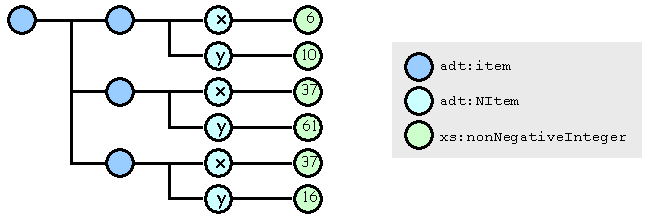
</asl:element>The schema reports that in the following snippet XML, the two first polygon definitions are valid, the two last invalid.
<polygon points="x=6, y=10, x=37, y=61, x=37, y=16"/>
<polygon points="6, 10, 37, 61, 37, 16"/>
<polygon points="x=6, y=10, x=37, y=61, x=37"/><!-- "y" value missing -->
<polygon points="6, 10, x=37, y=61, 37, 16"/><!-- heterogeneous value pairs -->Notice that the last polygon definition is invalid, but it is still possible to design a schema that allow heterogeneous value pairs. The same internal data model built for the 2 first polygon definitions is represented below : [TODO: change in this picture adt:item with adt:XComponent]The content model may also be slightly modified thanks to an interim step and XCL :
<asl:text item-name="x" item-value="{current()}" ref-type="xs:nonNegativeInteger"/>
...will produce a named item accessible with ./*/x, whereas :
<asl:text ignore="yes" ref-type="xs:nonNegativeInteger">
<asl:interim>
<xcl:attribute name="x" value="{current()}"/>
</asl:interim>
</asl:text>
...will produce an XML attribute accessible with ./*/@x. Any artifact other than a matcher put in the context will be used to build the typed data. | |
As matchers are tested sequencially, order is significant when lexical values are overlapping.
For example, the lexical values of xs:boolean are "true", "false", "0", "1" ; the two last are also in the lexical values of xs:integer ; the following types may not give the same typed data :
<asl:attribute name="booleanOrInteger">
<asl:text ref-type="xs:boolean"/>
<asl:text ref-type="xs:integer"/>
</asl:attribute>
<asl:attribute name="integerOrBoolean">
<asl:text ref-type="xs:integer"/>
<asl:text ref-type="xs:boolean"/>
</asl:attribute>"1" will return a xs:boolean with the first type, and an xs:integer in the second.
This is paricularly important when the xs:string type is involved, because any textual data is at least a string. When involved, this type should always appear at the end of a definition.
The xs:string type may be used as a fallback type.
When a type is defined, it may be based on another type. In this case, the value of the upper type becames the value of the new type defined. Additional items may be produced with the remainder of the upper type. Assertions can be used to restrict the scope of the values of the upper type.
For example, the polygon type defined previously may be used to define a triangle type and a square type :
<asl:type name="polygon">
<!-- the definitions used in the previous example -->
</asl:type>
<asl:type base="polygon" name="triangle">
<asl:assert test="{count( ./* ) = 3}"/>
</asl:type>
<asl:type base="polygon" name="square">
<asl:assert test="{count( ./* ) = 4}"/>
<!--insert other assertions to check the angles-->
</asl:type>may cover the data value semantics, and comparison between values expressed in different lexical spaces is possible ; for example, which temperature is colder than the other ? "31°F" or "0°C" ?
<asl:type base="xs:int" init="{.}" name="temperature">
<asl:choice>
<asl:text ignore="yes" min-occurs="0" value="°C"/>
<asl:text ignore="yes" min-occurs="0" value="°F">
<asl:interim>
<xcl:update operand="{ (. - 32) * 5 div 9 }" referent="{$asl:data}"/>
</asl:interim>
</asl:text>
</asl:choice>
</asl:type>As shown above, a typed data is initialized with an xs:int (init="{.}" keeps the typed data given by the base type). The remainder is parsed according to the inner declarations. When the string "°F" matched, the value stored previously is updated with the <xcl:update> element.
Functions may be bound to a type for the following purposes:
Functions are bound to a type by naming them in the type definition with attributes:
<asl:type compare-with="geom:compare-polygon" name="geom:polygon"
parse-with="geom:polygon">
...
</asl:type>
EXP may be used advantageously to define such functions, specifically when functions are defined as macro functions. See integration with EXP.
The @compare-with attribute contains the qualified name of a function involved for comparison. This function is automatically invoked with 2 arguments. When an XPath expression uses a comparator, like $poly1 <= $poly2, the type of the first argument $poly1 determine which function to call. Then the function associated is called with the 2 arguments in parameters. If necessary, the second argument may be cast to the same type of the first argument before invoking the function. The function involved return a number that is 0 if the arguments are equal or not comparable, negative if the first argument is less than the second one, or positive if the first argument is greater than the second one.
When this attribute is missing, the arguments are compared as indicated in the XPath specification.
EXP may be used advantageously to define such functions. Moreover, several comparison functions may be defined, and each application is free to use which comparison function to use. For example, what to compare when 2 polygons are compared ? The number of points ? The area ? The perimeter ? See integration with EXP.
This function is those which will be used for casting operations.
[TODO]When typed datas are parsed while validating an XML document, it is often usefull to bind the typed data to the nodes on which a type is defined. For example, if an attribute is defined as a xs:date the typed data bound to it will reflect this type, which can be very usefull when ordering relationships occur : a sort on a set of such attributes should be performed on the typed data, not on the string value of the attribute. The mechanism that allows to bind a typed data to an XML node is called "data augmentation" which consists on augmenting the amount of informations of the XML document on its infoset (which is also often referred to "Post Schema Validation Infoset", or PSVI).
allows to augment the amount of informations of an XML document while validating on user request. In this case, comparison operations made with XPath or functions that imply an order relation between item such as a sorting function must apply on the bound typed data, not on the raw textual data.
As the schemata in use are generally defined by the processor instance involved when validating, several different typed data might be bound to the same node ; those to consider is those set by the same processor instance that performs the validation. In other words, typed datas are bound to nodes in the scope of a processor instance. As the <asl:validate> element allows to define locally a schema not known by the processor instance (or more precisely by its catalogs), it is not recommended to perform several validation on the same parsed XML document within the same processor instance with different schema instances. In this case, the last schema applied will bind new typed data if it redefines them ; others typed data will remain the same.
Augmented datas must be taking in charge in s ; non applications such as XSLT are encouraged to do so.
The @augment attribute of the <asl:validate> element indicates whether typed datas must be bound to nodes defined with a type or not.
| Infoset augmentation with a typed data | |
|---|---|
In this example, a weather report indicates town temperatures expressed in °C as well as in °F. The type of the @temp attribute is those defined in a previous example. <weather-report> <town date="2005/09/09" name="Paris" temp="21°C"/> <town date="2005/09/08" name="Paris" temp="22°C"/> <town date="2005/09/09" name="Vladivostok" temp="32°F"/> <town date="2005/09/07" name="Paris" temp="20°C"/> <town date="2005/09/08" name="London" temp="23°C"/> </weather-report> The following snippet code simply parse the XML file, and validate it with the schema within which the expected type is defined ; then the towns are displayed in temperature order thanks to the xcl:sort() function :
<xcl:parse name="wr" source="file:///path/to/weather-report.xml"/>
<asl:validate augment="yes" node="{ $wr }" schema="file:///path/to/schema.asl"/>
<xcl:for-each name="town" select="{ xcl:sort( $wr/weather-report/town, @temp ) }">
<xcl:echo value="{ $town/@temp } { $town/@name } { $town/@date }"/>
</xcl:for-each>
Output : 32°F Vladivostok 2005/09/09 20°C Paris 2005/09/07 21°C Paris 2005/09/09 22°C Paris 2005/09/08 23°C London 2005/09/08 As expected, 32°F is placed before 20°C. If the @augment attribute of the <asl:validate> element was set to false, the temperatures will be sorted in lexical order, so 32°F would be placed at the last position. To force a lexical order on the augmented infoset, it is also possible to wrap the sort criterion with the string() function : string( @temp ). | |
[TODO: Distinct 'element classes' and 'structures' : the former are like substitution groups, the latter are related to typed elements]
All materials defined within an must be bound to the target namespace URI declared by the @target attribute of the root element, <asl:active-schema>. When an XML document is a mix of materials bound to several namespaces URI, each namespace URI for which the bounded materials need to be controlled must have its own schema.
<?xml version="1.0" encoding="iso-8859-1"?>
<asl:active-schema asl:version="1.0" schema-version="1.0" target="acme" xmlns:asl="http://www.inria.fr/xml/active-schema" xmlns:acme="http://www.acme.com/my-schema"> <!-- acme material definitions here --> </asl:active-schema>
Many elements are used for both defining a material or refering to a defined material (<asl:element name="..."> and <asl:element ref-elem="...">). Sometimes, the reference to a material may be inline, sometimes it can't. That's the case of elements that are always referred to definitions located on the top level. On the opposite, attributes, types, and text definitions are not obliged to be located on the top level, and then can be used as inline references.
Many informations inside an deals with namespace URIs ; instead of pointing out directly namespace URIs, which are generally long strings, always uses a prefix bound to a namespace URI as a more convenient mean.
For example, the @target attribute of the schema is a prefix ; the @ref-ns attribute in attribute and element references is also a prefix.
As usual with XML namespaces, only the bounded namespace URI matters. Schema designers must define the appropriate namespaces declarations when they are using prefixes in attributes values.
The @ref-ns attribute in attribute and element references is a prefix bound to a URI. However, the special following prefixes may be used to refer to namespaces that have a contextual role :
|
The ##targetNamespace used in W3C XML Schema has not its equivalent in ta ; users just have to use the same prefix as those specified in the @target attribute of the root element. |
The xml prefix may also be specified without any particular precaution (the appropriate namespace declaration is always auto-declared). On the contrary, the xmlns prefix must not be specified ; can't constraint namespace declarations because they have a particular meaning in XML.
may be mixed with other schemata technologies to add constraint types not supported. The schemata supported are implementation dependant.
Moreover, legacy schemata doesn't necessary deal with foreign material inclusion in XML instances ; elements and attributes that belong to other namespaces and that was not plan to be present will be normally forbidden.
allow to "patch" existing schemata (of course including ta), in order to :
This is particularly interesting when users are dealing with several third-party schemata that has not been written to accept materials in foreign namespaces.
| Schemata patching | |
|---|---|
A company uses multiple schema instances at different level :
Each level registers its schemata in a catalog. In this example, an element is defined at the top level with a legacy public DTD that contains :
<!ELEMENT acme:order (acme:ship-to, acme:item*)>
<!ATTLIST acme:order xmlns:acme CDATA #FIXED "http://www.acme.com/order"
id CDATA #REQUIRED>
The company needs to patch the DTD to allow XHTML content to be inserted inside <acme:order>. A catalog at the intermediate level simply refers to the following schema : <?xml version="1.0" encoding="iso-8859-1"?> As this schema is registered in a catalog close to the application, it will be used first. The <asl:apply-definition> element indicates to use the next schema in the catalog list, that is to say the DTD. The <asl:fallback> element is used when an unexpected attribute or element is encountered when applying the definitions. Its @mode attribute indicates if it has to be ignored, skipped, or traversed. If the XHTML content had to be inserted inside <acme:order> and before <acme:ship-to>, the element definition would be simply :
<asl:element name="acme:order">
<asl:sequence>
<asl:element max-occurs="unbounded" min-occurs="0" ref-ns="xhtml"/>
</asl:sequence>
<asl:apply-definition/>
</asl:element>
An application of that company have to deal with a new attribute (@date). Moreover, the order ID follows a specific text structure. Once again, a new schema is registered in the application's nearest catalog : <?xml version="1.0" encoding="iso-8859-1"?> | |
Schemata are organized in an ordered list ; each item of the list is given by a catalog (a single catalog may deliver several items). Schemata are ordered in the order they are delivered by catalogs.
When an element refers to an attribute that is already referred in a schema that has a less priority, the attribute must be checked only once : the schemata that has a less priority must not check it.
When a specific schema "overrides" a definition (attribute, element, type, etc), those used must be those that overrides even if it is referred from a schema that has a less priority. For example, if an attribute definition uses a named type defined in the same schema instance, but another schema instance that has a higher priority redefines this type and preserve the attribute, the attribute will be checked with the redefinition of the type.
is part of technology and then, fully integrated to features. Particularly, any other module may be used in a schema.
One of the most useful module may be XCL, because it offers the ability to go further with a procedural approach where the ASL declarative model find its limits. For example, an interim step could be optional by putting it inside an <xcl:if> statement ; schemata designers should use such features when they can't express a @max-occurs constraint on a single expression. Anyway, XCL enhance the power of because it may be used to build contextual lists of materials.
Modules that provide accesses to remote data sources may be also very useful.
As explained in "managing ", many storage units can be used to build a schema. This feature is particularly useful when a schema is intended to be shared with third-parties. An access to a RDBMS is not necessarilly public, and the snippet schema above would fail. When designing a schema, it is convenient to make them neutral if they have to be shared ; a private additionnal schema should then cover the non-exportable part that accesses to the RDBMS.
As explain before, EXP can be advantageously used to provide complex functions used when initializing typed datas, to specify a counterpart function for a type, or to specify a comparison function. The EXP module defined must be bound to the same namespace URI as the schema. The EXP module where these functions has been defined must be known by the processor instance that unmarshals the schema; see the EXP specification for this purpose, or the chapter about integration with .
In this cases and others, it may be convenient to define macro-functions in EXP.
Additionally, several of this functions could be defined in a module, and a schema could use one or another of this function.
For example, when comparing a polygon, one could:
According to the relevant application, one of this methods or the other could be used. Close to the application, a schema could specify which one use.
| Macro functions used as comparison functions | |
|---|---|
In this example, assume that the type defined previously is labelled geom:polygon-definition, with the variant where x and y are stored in attributes of a point, and with the approriate namespace declarations for the geom and math prefixes (assuming that a math module is also provided). Within a module definition, the expected functions are declared as macro-functions :
<exp:extended-function name="geom:compare-points">
<xcl:set value="{count( $exp:args[1]/* ) - count( $exp:args[2]/* )}"/>
</exp:extended-function>
<exp:extended-function name="geom:compare-perimeters">
<xcl:set value="{geom:perimeter( $exp:args[1] ) - geom:perimeter( $exp:args[2] )}"/>
</exp:extended-function>
<exp:extended-function name="geom:compare-areas">
<xcl:set value="{geom:area( $exp:args[1] ) - geom:area( $exp:args[2] )}"/>
</exp:extended-function>
<exp:extended-function name="geom:perimeter">
<xcl:set name="perimeter" value="{number(0)}"/>
<xcl:set name="pt1" value="{$exp:args[1]/*[1]}"/>
<xcl:for-each name="pt2" select="$exp:args[1]/*[ position()>1 ]">
<xcl:set name="p"The perimeter function could be better : for example, it could test before if the attribute "perimeter" exists and return it, otherwise it performs the computation and set the attribute for other usage. The first application could use this schema:
<asl:type compare-with="geom:compare-points" init="void" name="geom:polygon"The second one could use:
<asl:type compare-with="geom:compare-perimeters" init="void" name="geom:polygon" | |
There is neither inclusion nor import mechanism in . doesn't define itself how to retrieve different schema components : it delegates the task to a processor instance that relies itself on catalogs. For this purpose, s are useful because :
Moreover, may be used for other purpose than schema instance retrieval : when defining a schema, it may be useful to define EXP resources (such as functions, as shown before) that will be use in schemata instances.
Here is a snippet instance that bounds a namespace URI to several resources :
<cat:uri name="http://www.acme.com/geom">
<cat:entry key="exp:module" value="acme/module.exp"/>
<cat:entry key="asl:schema" value="acme/schema.asl"/>
<cat:entry key="asl:schema" value="acme/messages.asl"/>
<cat:entry key="asl:schema" value="acme/messages-fr.asl"/>
</cat:uri>See the specification for further details.
allows to define data types with tags, as explained in a previous chapter. However, also uses built-in data types ; the specification provides several built-in libraries for data types that may be used in , including the well known W3C XML Schema data type library (the specification adapts this library to be used in technologies). Built-in data type libraries are pre-compiled schema instances ; a pre-compiled schema instance may contain any material definition : types, attributes, elements... Pre-compiled schema instances
The specification defines an other kind of data type, called marker types, that can't be used in instances, but are part of the technologies. As this specification is also an application, such types can be referred in this document ; just notice that they can't be used as is in instances : an instance can use only XML-unstructured raw data as specified in the specification.
The <asl:desc> element may be used inside material references and assertions for documentation purposes.
<asl:attribute
min-occurs="{ 1 - number( count( asl:document()/asl:active-schema/asl:element[ not( @name ) ] ) = 0 ) }"
name="name" type="xs:QName">
<asl:desc id="asl:nameAttrOnTopLevelElem-desc" xml:lang="en">
The top level <at:element>asl:element</at:element> elements must have a <at:attribute>name</at:attribute> attribute,
except one of them that can omit it.
</asl:desc>
</asl:attribute>
Schema client handlers may expose a description if one available instead of an error message when an unexpected content is encountered.
The <asl:message> element is a top level element used to redefine multi-lingual messages :
<asl:message ref-desc="asl:nameAttrOnTopLevelElem-desc" xml:lang="fr">
L'élément de premier niveau <at:element>asl:element</at:element> doit avoir un attribut <at:attribute>name</at:attribute>,
excepté pour un seul d'entre eux qui a le droit de l'omettre.
</asl:message>
<asl:message ref-desc="asl:nameAttrOnTopLevelElem-desc" xml:lang="x-klingon">
Dol yor Hoch <at:element>asl:element</at:element> boq <at:attribute>name</at:attribute> choq,
Dugh bachHa' tuqnIgh chaw' wogh.
</asl:message>
When a schema client handler needs a description, it may hold an ordered list of preferred languages ; if a message or description exists for the language given, it will be chosen ; otherwise, the description will be used as default language.
|
Usually, a default language is set on the schema root element with @xml:lang ; each message definition should redefine the @xml:lang value as expected. |
Schema designers may find convenient to insert descriptions in a single master language only. Translations could be added in separated documents (1 per language). |
Additionally, the asl:message() function may be used to format messages. This function can be used in an active sheet to report validation errors.
Users are responsible of their models, and should not deploy them before testing them seriously. For example, the following model will always raise an error when involved, because the first sequence element will consume all <foo> elements, whereas the next sequence element requires one !
<asl:sequence>
<asl:element max-occurs="unbounded" min-occurs="0" ref-elem="foo"/>
<asl:element max-occurs="1" min-occurs="1" ref-elem="foo"/>
</asl:sequence>
Of course, some schemata may not present such obvious inconsistency.
A non-deterministic content model is a grammar-based content model where the schema processor has at most one possible choice.
There are no non-deterministic content model in an , because the basic processes don't allow such case to happened. The major rule in ta is that a candidate material matches or doesn't match a primitive model, where its material is read sequencially.
Thus, a write playing is still available in to express any arbitrary complex content model, without causing a schema inconsistency.
For example, the familiar following pattern is an unambiguous pattern which is not deterministic and can't be rewritten in a deterministic form :
(odd, even)*, odd?
A DTD containing this declaration would reject it. On the contrary, a valid may be written to express the same content model :
<asl:step max-occurs="unbounded" min-occurs="0">
<asl:sequence>
<asl:element
max-occurs="{ number( not( asl:candidate()/preceding-sibling::odd )
or ( name( asl:candidate()/preceding-sibling::*[1] ) = 'even' ) }"
min-occurs="0" ref-elem="odd"/>
<asl:element
max-occurs="{ number( name( asl:candidate()/preceding-sibling::*[1] ) = 'odd' ) }"
min-occurs="0" ref-elem="even"/>
</asl:sequence>
</asl:step>This step is refactoried as long as there is a candidate element that is alternatively <odd> then <even>. Each time that this step is applied, the sequence model contains a single optional element : alternatively <odd> and <even>.
The following valid may also be written to express the same content model :
<asl:sequence id="odd-even-seq">
<asl:element max-occurs="1" min-occurs="0" ref-elem="odd">
<asl:interim min-occurs="0">
<asl:sequence>
<asl:element max-occurs="1" min-occurs="0" ref-elem="even">
<asl:interim min-occurs="0">
<asl:use ref-id="odd-even-seq" scope="global"/>
</asl:interim>
</asl:element>
</asl:sequence>
</asl:interim>
</asl:element>
</asl:sequence>As long as an element is matched, it is followed by an optional element, alternatively <odd> and <even>.
A short set of instructions is defined to invoke a schema. These tags have to be used inside an active sheet that is not a schema instance. While running an active sheet, one often need to parse XML documents, validate them, and then transforming them ; the <asl:validate> element has been designed for this purpose.
As explained in "integration with ", the best way to invoke schemata, is to register them in an and let the engine do the job. However, as this approach is efficient with schemata targetting a namespace URI, it can't be done as is with a schema that has no namespace URI target ; there are 3 ways to deal with such a schema :
Several storage units (files) may be used to build a schema. Furthermore, a single XML document may be validated by several schemata, for example when several namespaces are used in the instance.
A schema client handler that expects a specific schema, for example to perform a validation on an element, launches a schema request.
Once a schema request is launched, the schema client handler must resolve and hold all storage units (files) that are composing the schema ; the schema client handler must then use the schemata hold for next schema requests.
The schemata are processed in the order in which they have been retrieved ; it is particularly important when using the <asl:apply-definition> element. The tip is to use the catalog as a register that handles schema references ; schemata are unmarshalled only on request, and keep unmarshalled for next usages.
[TODO]
[TODO]
s may be validate by engine while unmarshalling or before unmarshalling. While unmarshalling, only active tags are checked.
Errors are categorized in the following types :
Schema client handlers are free to process errors as they want. Errors are just reported informations that denotes that the engine has noticed an unexpected content inside an XML document, regarding to the schemata that have been used by the engine.
[TODO: Draw up the list of standard errors (QName)]
When validating, a report that holds the errors found is created.
An application that perform validations may use such reports to produce an XML output for specific processing. For example, by transforming it in HTML for an end user, or by transforming it in text for logging. For this purpose, the report provided is a cross operable object that contains informations about the errors :
Implementations should provide high-level structured error report and XSLT stylesheet to display them in a user-friendly fashion.
| ASL | : | Active Schema Language |
| ASL namespace URI | : | http://www.inria.fr/xml/active-schema |
| Usual prefix | : | asl |
Some features listed here are not used inside a schema, but may appear in other XML documents or active sheets. See externalisable features.
 | Must be an adt:expression that computes an object of the type expected. |
 | Must be a hard-coded value (litteral) |
 | Can be either a hard-coded value or an adt:expression |
 | This material may be missing |
 | Denotes a value to use by default |
 | Allows a read operation. |
 | Allows a write operation. |
 | Allows a rename operation. |
 | Allows an update operation. |
 | Allows a delete operation. |
Root element for an .
unmarshal phase
The schema handles all definitions found at the top level.
runtime phase
An object of the type asl:active-schema is set to the current object, so that schema client handlers can use it.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. target adt:prefix The namespace URI targeted by this schema. A namespace declaration (xmlns:foo="...") must be done for the prefix specified in this attribute (target="foo"). empty The definitions of the schema are not bound to a namespace URI. schema-version xs:string The version of this schema. asl:version xs:string The version of ASL.
The <asl:element> element is both used to define an element, and to refer to one :
[FIXME: An optional '@match' attribute would be very convenient ; it would contain a pattern, and several declarations could be done for the same element. Easy to implement.]
- when <asl:element> is a top level element, it is used as an element definition, for which the @name attribute contains the qualified name of the element to define. When missing, the declaration is used as a fallback definition for all elements that has not a proper definition.
- otherwise, one of the following attributes must be used :
- @ref-elem to refer to an element definition,
- @ref-class to refer to an element of a specific class,
- @ref-ns to refer to an element bound to a specific namespace URI.
runtime phase
- An element definition behaves like a step (see <asl:step>).
- An element reference opens a context and runs its subactions; it feeds the upper context with a matcher for this element; this matcher may handle an interim step if its context was containing one.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. name xs:QName The name of the element. root Indicates wether or not the defined element must be root when used, or can be root. xs:string always When this element is used, it must be root. sometimes This element may be root. never When this element is used, it mustn't be root. ref-elem xs:QName The name of an element. ref-class xs:QName The name of an element class. ref-ns A reference to a namespace URI. xs:string #any Any namespace URI. #other Any namespace URI different of those specified in the host schema. #local No namespace URI. adt:prefix A prefix used in a namespace declaration. match adt:pattern A pattern used to filter elements. When missing, all elements matches the definition. This definition doesn't apply to candidate elements that doesn't match this pattern. Several element definitions may refer to the same element each having a specific pattern. The first pattern matching is applied. min-occurs Indicates the minimum times the step must be repeated. xs:nonNegativeInteger 1 The step is at least processed once. xs:nonNegativeInteger The number of times the step must be processed. max-occurs Indicates the maximum times the step may be repeated. xs:nonNegativeInteger 1 The step is at most processed once. xs:string unbounded The step is processed as long as there is something to process. xs:nonNegativeInteger The number of times the step may be processed.
The <asl:attribute> may be used :
- as a global attribute definition (the definition is under the root element),
- as a local attribute definition,
- as an attribute reference.
The <asl:attribute> element is both used to define an element, and to refer to one :
- an attribute definition must use the @name attribute, which contains the qualified name of the attribute to define.
- otherwise, one of the following attributes must be used :
- @ref-attr to refer to an attribute definition,
- @ref-ns to refer to an attribute bound to a specific namespace URI.
A global attribute definition can be referenced from any other schema. A local attribute definition can be referenced only from the schema that defines it.
runtime phase
- An attribute definition behaves like a step (see <asl:step>).
- An attribute reference opens a context and runs its subactions; it feeds the upper context with a matcher for this element; this matcher may handle an interim step if its context was containing one.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. name xs:QName The name of the attribute. ref-attr xs:QName The name of an attribute. ref-type xs:QName The name of a type in an attribute definition. ref-ns A reference to a namespace URI. xs:string #any Any namespace URI. #other Any namespace URI different of those specified in the host schema. #local No namespace URI. adt:prefix A prefix used in a namespace declaration. min-occurs Indicates the minimum times the step must be repeated. xs:nonNegativeInteger 1 The step is at least processed once. xs:nonNegativeInteger The number of times the step must be processed. max-occurs Indicates the maximum times the step may be repeated. xs:nonNegativeInteger 1 The step is at most processed once. xs:string unbounded The step is processed as long as there is something to process. xs:nonNegativeInteger The number of times the step may be processed.
Defines an item when building a typed data. An item may have a name or may be unnamed.
runtime phase
Opens a context and runs its subactions; builds an item with the data found in the context; feeds the upper context with an item.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. name xs:QName The name of the item.
Set the boundaries of a partial content model. A step may contains substeps. It is a convenient container for primitive content models and other steps. A step is always unstable.
runtime phase
Opens a context and runs its subactions; invoke the schema client handler with the list of matchers found in the context.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. min-occurs Indicates the minimum times the step must be repeated. xs:nonNegativeInteger 1 The step is at least processed once. xs:nonNegativeInteger The number of times the step must be processed. max-occurs Indicates the maximum times the step may be repeated. xs:nonNegativeInteger 1 The step is at most processed once. xs:string unbounded The step is processed as long as there is something to process. xs:nonNegativeInteger The number of times the step may be processed.
A container step that denotes that the current content model must be leaved temporarily. The inner models are applied on the next candidates only if the host step has matched. When ending, the host content model goes on (default behaviour). An interim step is always unstable.
runtime phase
Opens a context and runs its subactions; invoke the schema client handler with the list of matchers found in the context.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. min-occurs Indicates the minimum times the step must be repeated. xs:nonNegativeInteger 1 The step is at least processed once. xs:nonNegativeInteger The number of times the step must be processed. max-occurs Indicates the maximum times the step may be repeated. xs:nonNegativeInteger 1 The step is at most processed once. xs:string unbounded The step is processed as long as there is something to process. xs:nonNegativeInteger The number of times the step may be processed. replace Indicates wether or not the host model must be interrupted or continued, after running the interim step. xs:string yes The interim model replaces the host model that musn't continue. no The interim model doesn't replace the host model that must continue.
Defines a sequence of elements and/or text content. A sequence is always stable.
runtime phase
Opens a context and runs its subactions; invoke the schema client handler with a sequence of matchers found in the context.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused.
Defines a choice of elements and/or text content.
runtime phase
Opens a context and runs its subactions; invoke the schema client handler with a choice of matchers found in the context.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. repeating Indicates how the step must be repeated. xs:string stable The content list is kept as is. unstable The content list is unstable ; it must be refactoried. min-occurs Indicates the minimum times the step must be repeated. xs:nonNegativeInteger 1 The step is at least processed once. xs:nonNegativeInteger The number of times the step must be processed. max-occurs Indicates the maximum times the step may be repeated. xs:nonNegativeInteger 1 The step is at most processed once. xs:string unbounded The step is processed as long as there is something to process. xs:nonNegativeInteger The number of times the step may be processed.
Defines a list of elements and/or text content to select.
runtime phase
Opens a context and runs its subactions; invoke the schema client handler with a selection of matchers found in the context.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. repeating Indicates how the step must be repeated. xs:string stable The content list is kept as is. unstable The content list is unstable ; it must be refactoried. min-occurs Indicates the minimum times the step must be repeated. xs:nonNegativeInteger 1 The step is at least processed once. xs:nonNegativeInteger The number of times the step must be processed. max-occurs Indicates the maximum times the step may be repeated. xs:nonNegativeInteger 1 The step is at most processed once. xs:string unbounded The step is processed as long as there is something to process. xs:nonNegativeInteger The number of times the step may be processed.
Draws up a list of exceptions.
runtime phase
Opens a context and runs its subactions; the matchers found in the context are the exceptions for a host matcher.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused.
Defines a block. This element is very useful when the same definitions have to be reused several times.
runtime phase
Simply runs its subactions.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused.
Uses an identifiable element or its content.
runtime phase
Simply runs the action or the subactions referenced.
[TODO: content definition]
Attributes Name Type Value ref-id xs:QName The identifier referenced. scope Indicates wether or not the target element must be whole used or only its content. xs:string global The element itself is used as is. content The element itself is ignored: only its content is used.
Checks an assertion. An assertion evaluated to false denotes that the model that uses it fails.
runtime phase
If the assertion is not expressed with the @test attribute, runs its subactions and evaluate the current object as a boolean.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. test adt:boolean The test to compute.
Defines a text matcher. A text matcher is used to match attribute values and text content. A simple text matcher is defined with one of the following attributes:
[TODO: @list would be convenient to match list of text values (by handling an 'adt:list' typed data) ; easy to implement]
- @value to match a text value,
- @match to match a regular expression,
A complex text matcher refers to a type either with the @ref-type attribute, or with a type defined within; in this last case, the text matcher can't have an interim step.
runtime phase
Opens a context and runs its subactions.
- for simple text matcher or text matcher that refers to a type, the context may contain an interim step to invoke when the matcher matches;
- otherwise, the context should contain a matcher (usually a type matcher defined within this text definition) or is ignored.
Feeds the upper context with a text matcher.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. min-occurs Indicates the minimum times the step must be repeated. xs:nonNegativeInteger 1 The step is at least processed once. xs:nonNegativeInteger The number of times the step must be processed. max-occurs Indicates the maximum times the step may be repeated. xs:nonNegativeInteger 1 The step is at most processed once. xs:string unbounded The step is processed as long as there is something to process. xs:nonNegativeInteger The number of times the step may be processed. value xs:string A text value. match xs:string A regular expression. ref-type xs:string A reference to a type. canonical-equivalence Enables or disables the canonical equivalence of a regular expression, that is to say that two characters will be considered to match if, and only if, their full canonical decompositions match; for example, the expression "a\u030A" will match the string "å". xs:boolean true enables the canonical equivalence. false disables the canonical equivalence. case-insensitive Indicates wether a regular expression is case-sensitive or not. xs:boolean true enables case-insensitive matching. false disables case-insensitive matching. dot-all Indicates wether or not a regular expression enables dotall mode. In dotall mode, the expression . matches any character, including a line terminator. xs:boolean true matches line terminators. false does not match line terminators. mutli-line Indicates wether or not a regular expression is in multi-line mode. In multiline mode the expressions ^ and $ match just after or just before, respectively, a line terminator or the end of the input sequence. xs:boolean true ^ and $ doesn't match at the beginning and the end of the entire input sequence. false ^ and $ matches at the beginning and the end of the entire input sequence. ignore Indicates wether this matcher must build an item or not. xs:string yes when matched, the host typed data remains unchanged. no when matched, this matcher builds an item on behalf of the host typed data. item-name xs:QName The name of the item to build. item-value any The value of the item to build.
Defines a data type.
The <asl:type> element may be used :
- as a global type definition (the definition is under the root element) that must have a name,
- as a local type definition, that can be anonymous.
When the type to define is based on an another type (@base), it is possible to specify how to initialize (@init) the typed data before parsing, and what to parse (@parse).
A type is defined with steps that draw up lists of text matchers and other type matchers.
unmarshal phase
A type definition may be registered to the schema either by name or by ID:
- A global type definition is registered to the schema by its name.
- If a local type definition has an ID, it is registered to the schema as an identifiable reusable furniture.
runtime phase
- a global definition is not run at runtime; the schema simply holds the type definition and can deliver it on request ; when an attribute definition or a text matcher refers to such a type, the matcher given is a type matcher;
- a local definition feeds the upper context with a type matcher.
invokation phase
A type matcher is invoked when a text candidate must be checked. For this purpose, it opens a context and runs its subactions. The context is used to build the typed data. If the text candidate matched the type, the typed data feeds the upper context.
Errors raised by a type may be ignored by the schema client handler : when a type matcher failed to match a text data, another candidate type matcher may be used; an error is raised only when a candidate matcher is expected and that none matched.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. name xs:QName The name of the type. base xs:QName The name of a base type. init Indicates how to initialize the typed data before parsing. If this attribute is missing, the typed data is initialized with the typed data produced by the base type if it is a composite data or wrapped in a composite data. void the typed data is not initialized; when processing the subactions, if a type initializes its typed data, it will supply it to its parent type. any the object is used to initialize the typed data. parse Indicates what to parse after initialization. If this attribute is missing, the type will parse the remainder that has not been parsed by the base type. xs:string the text that this definition have to parse. compare-with xs:QName The name of a function. This function is automatically involved when a data of this type is involved in comparison operations in XPath expressions. parse-with xs:QName The name of a function. The function is involved to transform a data to a typed data of this type when this type is required. [FIXME: cast-with() is it a better attribute name ?]
Indicates to the schema client handler to apply the definitions of the next schema. The schemata list is built from catalogs and maintained by the schema client handler.
<asl:fallback> elements may be used within to indicate which foreign elements and attributes are authorized when applying definitions.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused.
A fallback matcher is used when an unexpected material (element or attribute) has been encountered when applying definitions (<asl:apply-definition>).
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. match adt:pattern The pattern to match. If an unexpected material doesn't match any <asl:fallback> element, an error is raised.
mode Indicates what to do with the unexpected material (element or attribute). xs:string ignore the material is considered absent skip (for elements only) the content of the element is considered to hold its place traverse the material and its content or value is checked
A description.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused.
An alternate message definition. This element is designed for multilingual support. When a <asl:desc> element is used in a schema, the current language specified with the @xml:lang is endorsed. The <asl:message> redefines any description in one or more languages (use 1 message element per language). It may be convenient to define a set of messages in a separate unit storage (file), usually 1 set of messages per language.
[TODO: content definition]
Attributes Name Type Value id xs:QName An identifier that allows the content to be reused. ref-desc xs:QName The description referenced.
- Priority : 0
The version of the ASL module to use. This attribute should be encountered before any ASL element, but it takes precedence on the element inside which it is hosted.
Property type: xs:anyURI $asl:ns-target is the target namespace URI of the schema.
Property type: xs:int $asl:min-occurs is the value of the min occurs value computed.
Property type: xs:int $asl:max-occurs is the value of the max occurs value computed.
Return: xml:node This function returns the candidate material to check or to insert, according to the using mode of the schema. However, if it is an element, it has no name because in an insert mode, the host application may use the schema to guess the list of elements available in the insert context.
In fact, the candidate material can be used only for positional testing.
Return: xml:element This function returns the element designated by the @name attribute used in the <asl:element> element.
Return: xml:document This function returns the document hosting the element or attribute that is processing by the schema.
Return: xs:string Returns the compacted form of a string, that is to say a string with no trailing spaces and for which contiguous spaces are replaced with a single space.
Arguments 1 xs:string The string to compact. Arguments 1 other The string value of the object will be compacted.
The following items are not designed to be used inside an , but inside an active sheet that is not a schema, that would use and refer to schemata.
Parses a schema.
[TODO: content definition]
Attributes Name Type Value name xs:QName The qualified name of the schema property to create. source io:x-file The schema file to parse. io:input The input stream schema to parse. xs:anyURI The URI of the schema to parse ; the schema will be looked up by the catalog known by the host processor instance. If the schema is stored in several storage units (files), the schema returned may be linked to all schema instances returned by the catalog. If a definition is expected on this schema and not found, the schema client handler will use the catalog for further lookup. xml:document The XML document to unmarshal to a schema instance.
Instruction used to perform a validation of a schema on a node. If no schema is specified (with the @schema attribute), the validation is performed with the schema found in the catalog known by the host processor instance
[TODO: content definition]
Attributes Name Type Value schema asl:schema The schema instance to use. xml:document The XML document to unmarshal to a schema instance. io:x-file The schema file to parse. io:input The input stream schema to parse. xs:anyURI The URI of the schema file to parse. node xml:node The node to validate.
report xs:Qame The name of the report property to produce. A property with this name is added to the data set. A report is a adt:list of asl:x-error.
deep Indicates whether a recursive validation must be performed or not. xs:string yes Perform a recursive validation. no Perform a surface validation. augment Indicates whether the infoset must be augmented with typed datas or not. xs:string yes Typed datas are bounded to nodes defined with a type. no Typed datas are used only for checking.
Instruction used to identify the material available on the given context. [TODO]
[TODO: content definition]
This element does nothing. It is an element container for canonical paths, and should not be hard-coded inside an active sheet. However, it could be generate anyway in an XML document and used by an application.
When created, this element contains all namespace declarations expected in the path, hosted either in the @path attribute or in the @rule-path attribute.
See "path element" and asl:x-error.
[TODO: content definition]
Attributes Name Type Value path xs:string A canonical path. rule-path xs:string A canonical path.
Return: xml:node Build a structured message with the object given. The message may be built with the locale language or with a specific language.
If no object is specifically provided, the object given is the current object when building the structured message.
Arguments 1 xs:QName The message ID. Arguments 1 xs:QName The message ID. 2 xs:string The language. Arguments 1 xs:QName The message ID. 2 xs:string The language or an empty string to force locale usage. 3 an object The object to use in the message.
Errors are created when performing a validation on an XML instance.
Operation Type Value Comment type() xs:QName asl:x-error This type string() xs:string The string value of an error is [FIXME: what ?]. attribute:: adt:map of xml:attribute A set of attributes (see below). Additional attributes may be set as specified in this specification. Any of the following predefined attributes may be shadowed by a specific one with the same name ; if removed, the original predefined attribute is unshadowed. @source-document xml:document The XML document that host the node that was checking. @schema asl:schema The schema that raised the error. @node xml:node The node that was checking. @candidate xml:node The candidate material in use, if any. @path xml:node The path element of the candidate or the node that cause the error. @rule-path xml:node The path element of the schema rule that raise the error. @reason-id xml:node The key of the error message. @type xml:node The key of the type of error.
Path element
The canonical path of a node is hosted in an attribute of the <asl:report> element (the @path or @rule-path attribute), called a path element.
This element contains the namespace declarations involved in the path.
The path is exposed as an expression to make easier use by an application.
This list is not exhaustive; it is a list of common modules usable by an engine that implements the specifications that implementors may use. Additional modules are welcome.
<asl:active-schema asl:version="1.0" target="asl" schema-version="1.0" xml:lang="en" xmlns:asl="http://www.inria.fr/xml/active-schema" xmlns:adt="http://www.inria.fr/xml/active-datatypes" xmlns:xs="http://www.w3.org/2001/XMLSchema-datatypes" xmlns="http://www.w3.org/1999/xhtml" xmlns:at="http://www.inria.fr/xml/active-tags/reference"> <asl:attribute name="asl:version" min-occurs="0" ref-type="xs:string"/> <asl:element name="asl:active-schema" root="always"> <asl:block id="asl:commonAttributes-block"> <asl:attribute ref-ns="#other" min-occurs="0" max-occurs="unbounded"/> <asl:attribute name="id" min-occurs="0" ref-type="xs:ID"/> </asl:block> <asl:attribute ref-attr="asl:version"/> <asl:attribute name="schema-version" min-occurs="0" ref-type="xs:string"/> <asl:attribute name="target" ref-type="att:ns-prefix"/> <asl:choice min-occurs="1" max-occurs="unbounded"> <asl:element ref-elem="asl:element"/> <asl:element ref-elem="asl:class"/> <asl:element ref-elem="asl:attribute"/> <asl:element ref-elem="asl:text"/> <asl:element ref-elem="asl:block"/> <asl:element ref-elem="asl:type"/> <asl:element ref-elem="asl:message"/> </asl:choice> </asl:element> <asl:block id="asl:occurs"> <asl:attribute name="min-occurs"> <asl:text ref-type="xs:nonNegativeInteger"/> <asl:text ref-type="adt:expression"/> </asl:attribute> <asl:attribute name="max-occurs"> <asl:text value="unbounded"/> <asl:text ref-type="xs:nonNegativeInteger"/> <asl:text ref-type="adt:expression"/> </asl:attribute> </asl:block> <asl:type name="asl:dynQName" parse-with="qname"> <asl:desc id="asl:dynamicQName-desc">A dynamic QName is either hard-coded or computed at runtime.</asl:desc> <asl:type ref-type="xs:QName"/> <asl:type ref-type="adt:expression"/> </asl:type> <asl:element name="asl:element"> <asl:use ref-id="asl:commonAttributes-block"/> <asl:attribute name="root" min-occurs="0" default="never"> <asl:text value="always"/> <asl:text value="sometimes"/> <asl:text value="never"/> </asl:attribute> <asl:select min-occurs="{ 1 - count( asl:element()/parent::asl:active-schema ) }"
max-occurs="{ $asl:min-occurs }"> <asl:desc id="asl:refAttrOnTopLevelElem-desc"> Non top level <at:element>asl:element</at:element> elements must have one of the following attributes : <at:attribute>ref-elem</at:attribute>, <at:attribute>ref-class</at:attribute>, or <at:attribute>ref-ns</at:attribute>. </asl:desc> <asl:attribute name="ref-elem" ref-type="asl:dynQName"> <asl:interim> <asl:select min-occurs="0" max-occurs="2"> <asl:use ref-id="asl:occurs"/> </asl:select> </asl:interim> </asl:attribute> <asl:attribute name="ref-class" ref-type="xs:QName"> <asl:interim> <asl:select min-occurs="0" max-occurs="2"> <asl:use ref-id="asl:occurs"/> </asl:select> </asl:interim> </asl:attribute> <asl:attribute name="ref-ns"> <asl:block id="asl:ref-ns"> <asl:type ref-type="adt:prefix"/> <asl:text value="#any"/> <asl:text value="#other"/> <asl:text value="#local"/> </asl:block> <asl:interim> <asl:select min-occurs="0" max-occurs="2"> <asl:use ref-id="asl:occurs"/> </asl:select> </asl:interim> </asl:attribute> </asl:select> <asl:attribute name="name" ref-type="xs:QName"
min-occurs="{ count( asl:element()/parent::asl:active-schema and asl:root()/asl:element[ not( @name ) ] ) }"
max-occurs="1"> <asl:desc id="asl:nameAttrOnTopLevelElem-desc"> The top level <at:element>asl:element</at:element> elements must have a <at:attribute>name</at:attribute> attribute, except one of them that can omit it. </asl:desc> </asl:attribute> <!--TODO : content definition--> </asl:element> <asl:element name="asl:attribute"> <asl:use ref-id="asl:commonAttributes-block"/> <asl:use ref-id="asl:occurs"/> <asl:attribute name="name" ref-type="xs:QName"
min-occurs="{ count( asl:element()/parent::asl:active-schema ) }"
max-occurs="1"> <asl:interim> <asl:select min-occurs="0" max-occurs="1"> <asl:attribute name="ref-type" ref-type="asl:dynQName" min-occurs="0"/> </asl:select> </asl:interim> </asl:attribute> <asl:attribute name="ref-attr" ref-type="asl:dynQName"
min-occurs="{ 1 - count( asl:element()/parent::asl:active-schema ) }"> </asl:attribute> <asl:attribute name="ref-ns"> <asl:use ref-id="asl:ref-ns"/> </asl:attribute> <!--TODO : content definition--> </asl:element> <asl:element name="asl:type"> <asl:attribute ref-ns="#other" min-occurs="0" max-occurs="unbounded"/> <asl:attribute name="name" min-occurs="{ count( asl:element()/parent::asl:active-schema ) }"
max-occurs="{ $asl:min-occurs }" ref-type="xs:QName"/> <asl:attribute name="id" max-occurs="{ 1 - count( asl:element()/parent::asl:active-schema ) }"
min-occurs="{ $asl:max-occurs }" ref-type="xs:ID"/> <asl:attribute name="base" ref-type="xs:QName" min-occurs="0" max-occurs="1"> <asl:interim> <asl:select min-occurs="0" max-occurs="2"> <asl:attribute name="init" ref-type="adt:expression" min-occurs="0"/> <asl:attribute name="parse" ref-type="adt:expression" min-occurs="0"/> </asl:select> </asl:interim> </asl:attribute> <asl:attribute name="compare-with" ref-type="xs:QName" min-occurs="0"/> <asl:attribute name="parse-with" ref-type="xs:QName" min-occurs="0"/> <!--TODO : content definition--> </asl:element> <asl:element name="asl:item"> <asl:use ref-id="asl:commonAttributes-block"/> <asl:attribute name="name" ref-type="xs:QName" min-occurs="0" max-occurs="1"/> <!--TODO : content definition--> </asl:element> <asl:element name="asl:apply-definition"> <asl:use ref-id="asl:commonAttributes-block"/> <!--TODO : content definition--> </asl:element> <asl:element name="asl:fallback"> <asl:use ref-id="asl:commonAttributes-block"/> <asl:attribute name="match" ref-type="adt:pattern"/> <asl:attribute name="mode" min-occurs="0"> <asl:text value="ignore"/> <asl:text value="skip"/> <asl:text value="traverse"/> </asl:attribute> </asl:element> <!-- TODO --> </asl:active-schema>
<asl:active-schema asl:version="1.0" xcl:version="1.0" target="asl" schema-version="1.0"
xml:lang="en" xmlns:asl="http://www.inria.fr/xml/active-schema" xmlns:xcl="http://www.inria.fr/xml/active-tags/xcl" xmlns="http://www.w3.org/1999/xhtml" xmlns:at="http://www.inria.fr/xml/active-tags/reference"> <!-- error messages for validation --> <asl:message id="asl:attributeExpected"> The <xml:attribute>{ name( value( @candidate ) ) }</xml:attribute> attribute is missing in the <xml:element>{ name( value( @node ) ) }</xml:element> element. { value( @path ) } Schema : { string( @schema-ns ) } { value( @rule-path ) } </asl:message> <asl:message id="asl:unexpectedAttribute"> The <xml:attribute>{ name( value( @candidate ) ) }</xml:attribute> attribute is unexpected in the <xml:element>{ name( value( @node ) ) }</xml:element> element. { value( @path ) } Schema : { string( @schema-ns ) } { value( @rule-path ) } </asl:message> <asl:message id="asl:badAttributeValue"> Bad value = "{ string( value( @candidate ) ) }" for the attribute <xml:attribute>{ name( value( @candidate ) ) }</xml:attribute> in the <xml:element>{ name( value( @node ) ) }</xml:element> element. { value( @path ) } Schema : { string( @schema-ns ) } { value( @rule-path ) } </asl:message> <!-- TODO --> </asl:active-schema>
This list is not exhaustive. Additional implementations are welcome.